tsfresh.feature_selection package¶
Submodules¶
tsfresh.feature_selection.benjamini_hochberg_test module¶
-
tsfresh.feature_selection.benjamini_hochberg_test.benjamini_hochberg_test(df_pvalues, hypotheses_independent, fdr_level)[source]¶ This is an implementation of the benjamini hochberg procedure that determines if the null hypothesis for a given feature can be rejected. For this the test regards the features’ p-values and controls the global false discovery rate, which is the ratio of false rejections by all rejections:
![FDR = \mathbb{E} \left [ \frac{ |\text{false rejections}| }{ |\text{all rejections}|} \right]](../_images/math/40805bea42d6f4ef764dca8bf9e6b7356aa4b76a.png)
References
[1] Benjamini, Yoav and Yekutieli, Daniel (2001). The control of the false discovery rate in multiple testing under dependency. Annals of statistics, 1165–1188 Parameters: - df_pvalues (pandas.DataFrame) – This DataFrame should contain the p_values of the different hypotheses in a column named “p_values”.
- hypotheses_independent (bool) – Can the significance of the features be assumed to be independent? Normally, this should be set to False as the features are never independent (e.g. mean and median)
- fdr_level (float) – The FDR level that should be respected, this is the theoretical expected percentage of irrelevant features among all created features.
Returns: The same DataFrame as the input, but with an added boolean column “relevant” denoting if the null hypotheses has been rejected for a given feature.
Return type:
tsfresh.feature_selection.relevance module¶
Contains a feature selection method that evaluates the importance of the different extracted features. To do so, for every feature the influence on the target is evaluated by an univariate tests and the p-Value is calculated. The methods that calculate the p-values are called feature selectors.
Afterwards the Benjamini Hochberg procedure which is a multiple testing procedure decides which features to keep and which to cut off (solely based on the p-values).
-
tsfresh.feature_selection.relevance.calculate_relevance_table(X, y, ml_task='auto', n_jobs=2, chunksize=None, test_for_binary_target_binary_feature='fisher', test_for_binary_target_real_feature='mann', test_for_real_target_binary_feature='mann', test_for_real_target_real_feature='kendall', fdr_level=0.05, hypotheses_independent=False)[source]¶ Calculate the relevance table for the features contained in feature matrix X with respect to target vector y. The relevance table is calculated for the intended machine learning task ml_task.
To accomplish this for each feature from the input pandas.DataFrame an univariate feature significance test is conducted. Those tests generate p values that are then evaluated by the Benjamini Hochberg procedure to decide which features to keep and which to delete.
We are testing
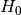 = the Feature is not relevant and should not be added
= the Feature is not relevant and should not be addedagainst
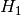 = the Feature is relevant and should be kept
= the Feature is relevant and should be keptor in other words
= Target and Feature are independent / the Feature has no influence on the target = Target and Feature are associated / dependentWhen the target is binary this becomes
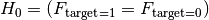
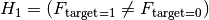
Where
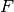 is the distribution of the target.
is the distribution of the target.In the same way we can state the hypothesis when the feature is binary
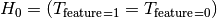
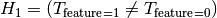
Here
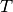 is the distribution of the target.
is the distribution of the target.TODO: And for real valued?
Parameters: - X (pandas.DataFrame) – Feature matrix in the format mentioned before which will be reduced to only the relevant features. It can contain both binary or real-valued features at the same time.
- y (pandas.Series or numpy.ndarray) – Target vector which is needed to test which features are relevant. Can be binary or real-valued.
- ml_task (str) – The intended machine learning task. Either ‘classification’, ‘regression’ or ‘auto’. Defaults to ‘auto’, meaning the intended task is inferred from y. If y has a boolean, integer or object dtype, the task is assumend to be classification, else regression.
- test_for_binary_target_binary_feature (str) – Which test to be used for binary target, binary feature (currently unused)
- test_for_binary_target_real_feature (str) – Which test to be used for binary target, real feature
- test_for_real_target_binary_feature (str) – Which test to be used for real target, binary feature (currently unused)
- test_for_real_target_real_feature (str) – Which test to be used for real target, real feature (currently unused)
- fdr_level (float) – The FDR level that should be respected, this is the theoretical expected percentage of irrelevant features among all created features.
- hypotheses_independent (bool) – Can the significance of the features be assumed to be independent? Normally, this should be set to False as the features are never independent (e.g. mean and median)
- n_jobs (int) – Number of processes to use during the p-value calculation
- chunksize (int) – Size of the chunks submitted to the worker processes
Returns: A pandas.DataFrame with each column of the input DataFrame X as index with information on the significance of this particular feature. The DataFrame has the columns “Feature”, “type” (binary, real or const), “p_value” (the significance of this feature as a p-value, lower means more significant) “relevant” (True if the Benjamini Hochberg procedure rejected the null hypothesis [the feature is not relevant] for this feature)
Return type:
-
tsfresh.feature_selection.relevance.combine_relevance_tables(relevance_tables)[source]¶ Create a combined relevance table out of a list of relevance tables, aggregating the p-values and the relevances.
Parameters: relevance_tables (List[pd.DataFrame]) – A list of relevance tables Returns: The combined relevance table Return type: pandas.DataFrame
-
tsfresh.feature_selection.relevance.get_feature_type(feature_column)[source]¶ For a given feature, determine if it is real, binary or constant. Here binary means that only two unique values occur in the feature.
Parameters: feature_column (pandas.Series) – The feature column Returns: ‘constant’, ‘binary’ or ‘real’
-
tsfresh.feature_selection.relevance.infer_ml_task(y)[source]¶ Infer the machine learning task to select for. The result will be either ‘regression’ or ‘classification’. If the target vector only consists of integer typed values or objects, we assume the task is ‘classification’. Else ‘regression’.
Parameters: y (pandas.Series) – The target vector y. Returns: ‘classification’ or ‘regression’ Return type: str
tsfresh.feature_selection.selection module¶
This module contains the filtering process for the extracted features. The filtering procedure can also be used on other features that are not based on time series.
-
tsfresh.feature_selection.selection.select_features(X, y, test_for_binary_target_binary_feature='fisher', test_for_binary_target_real_feature='mann', test_for_real_target_binary_feature='mann', test_for_real_target_real_feature='kendall', fdr_level=0.05, hypotheses_independent=False, n_jobs=2, chunksize=None, ml_task='auto')[source]¶ Check the significance of all features (columns) of feature matrix X and return a possibly reduced feature matrix only containing relevant features.
The feature matrix must be a pandas.DataFrame in the format:
index feature_1 feature_2 ... feature_N A ... ... ... ... B ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... Each column will be handled as a feature and tested for its significance to the target.
The target vector must be a pandas.Series or numpy.array in the form
index target A ... B ... . ... . ... and must contain all id’s that are in the feature matrix. If y is a numpy.array without index, it is assumed that y has the same order and length than X and the rows correspond to each other.
Examples
>>> from tsfresh.examples import load_robot_execution_failures >>> from tsfresh import extract_features, select_features >>> df, y = load_robot_execution_failures() >>> X_extracted = extract_features(df, column_id='id', column_sort='time') >>> X_selected = select_features(X_extracted, y)
Parameters: - X (pandas.DataFrame) – Feature matrix in the format mentioned before which will be reduced to only the relevant features. It can contain both binary or real-valued features at the same time.
- y (pandas.Series or numpy.ndarray) – Target vector which is needed to test which features are relevant. Can be binary or real-valued.
- test_for_binary_target_binary_feature (str) – Which test to be used for binary target, binary feature (currently unused)
- test_for_binary_target_real_feature (str) – Which test to be used for binary target, real feature
- test_for_real_target_binary_feature (str) – Which test to be used for real target, binary feature (currently unused)
- test_for_real_target_real_feature (str) – Which test to be used for real target, real feature (currently unused)
- fdr_level (float) – The FDR level that should be respected, this is the theoretical expected percentage of irrelevant features among all created features.
- hypotheses_independent (bool) – Can the significance of the features be assumed to be independent? Normally, this should be set to False as the features are never independent (e.g. mean and median)
- n_jobs (int) – Number of processes to use during the p-value calculation
- chunksize (int) – Size of the chunks submitted to the worker processes
- ml_task (str) – The intended machine learning task. Either ‘classification’, ‘regression’ or ‘auto’. Defaults to ‘auto’, meaning the intended task is inferred from y. If y has a boolean, integer or object dtype, the task is assumend to be classification, else regression.
Returns: The same DataFrame as X, but possibly with reduced number of columns ( = features).
Return type: Raises: ValueErrorwhen the target vector does not fit to the feature matrix or ml_task is not one of ‘auto’, ‘classification’ or ‘regression’.
tsfresh.feature_selection.significance_tests module¶
Contains the methods from the following paper about FRESH [2]
Fresh is based on hypothesis tests that individually check the significance of every generated feature on the target. It makes sure that only features are kept, that are relevant for the regression or classification task at hand. FRESH decide between four settings depending if the features and target are binary or not.
The four functions are named
target_binary_feature_binary_test(): Target and feature are both binarytarget_binary_feature_real_test(): Target is binary and feature realtarget_real_feature_binary_test(): Target is real and the feature is binarytarget_real_feature_real_test(): Target and feature are both real
References
| [2] | Christ, M., Kempa-Liehr, A.W. and Feindt, M. (2016). Distributed and parallel time series feature extraction for industrial big data applications. ArXiv e-prints: 1610.07717 https://arxiv.org/abs/1610.07717 |
-
tsfresh.feature_selection.significance_tests.target_binary_feature_binary_test(x, y)[source]¶ Calculate the feature significance of a binary feature to a binary target as a p-value. Use the two-sided univariate fisher test from
fisher_exact()for this.Parameters: - x (pandas.Series) – the binary feature vector
- y (pandas.Series) – the binary target vector
Returns: the p-value of the feature significance test. Lower p-values indicate a higher feature significance
Return type: Raise: ValueErrorif the target or the feature is not binary.
-
tsfresh.feature_selection.significance_tests.target_binary_feature_real_test(x, y, test)[source]¶ Calculate the feature significance of a real-valued feature to a binary target as a p-value. Use either the Mann-Whitney U or Kolmogorov Smirnov from
mannwhitneyu()orks_2samp()for this.Parameters: - x (pandas.Series) – the real-valued feature vector
- y (pandas.Series) – the binary target vector
- test (str) – The significance test to be used. Either
'mann'for the Mann-Whitney-U test or'smir'for the Kolmogorov-Smirnov test
Returns: the p-value of the feature significance test. Lower p-values indicate a higher feature significance
Return type: Raise: ValueErrorif the target is not binary.
-
tsfresh.feature_selection.significance_tests.target_real_feature_binary_test(x, y)[source]¶ Calculate the feature significance of a binary feature to a real-valued target as a p-value. Use the Kolmogorov-Smirnov test from from
ks_2samp()for this.Parameters: - x (pandas.Series) – the binary feature vector
- y (pandas.Series) – the real-valued target vector
Returns: the p-value of the feature significance test. Lower p-values indicate a higher feature significance.
Return type: Raise: ValueErrorif the feature is not binary.
-
tsfresh.feature_selection.significance_tests.target_real_feature_real_test(x, y)[source]¶ Calculate the feature significance of a real-valued feature to a real-valued target as a p-value. Use Kendall’s tau from
kendalltau()for this.Parameters: - x (pandas.Series) – the real-valued feature vector
- y (pandas.Series) – the real-valued target vector
Returns: the p-value of the feature significance test. Lower p-values indicate a higher feature significance.
Return type:
Module contents¶
The feature_selection module contains feature selection algorithms.
Those methods were suited to pick the best explaining features out of a massive amount of features.
Often the features have to be picked in situations where one has more features than samples.
Traditional feature selection methods can be not suitable for such situations which is why we propose a p-value based
approach that inspects the significance of the features individually to avoid overfitting and spurious correlations.