Overview on extracted features
tsfresh calculates a comprehensive number of features. All feature calculators are contained in the submodule:
This module contains the feature calculators that take time series as input and calculate the values of the feature. |
The following list contains all the feature calculations supported in the current version of tsfresh:
|
Returns the absolute energy of the time series which is the sum over the squared values |
Calculates the highest absolute value of the time series x. |
|
Returns the sum over the absolute value of consecutive changes in the series x |
|
|
Descriptive statistics on the autocorrelation of the time series. |
|
Calculates a linear least-squares regression for values of the time series that were aggregated over chunks versus the sequence from 0 up to the number of chunks minus one. |
|
Implements a vectorized Approximate entropy algorithm. |
|
This feature calculator fits the unconditional maximum likelihood of an autoregressive AR(k) process. |
|
Does the time series have a unit root? |
|
Calculates the autocorrelation of the specified lag, according to the formula [1] |
Useful for anomaly detection applications [1][2]. Returns the correlation from first digit distribution when |
|
|
First bins the values of x into max_bins equidistant bins. |
|
Uses c3 statistics to measure non linearity in the time series |
|
First fixes a corridor given by the quantiles ql and qh of the distribution of x. |
|
This function calculator is an estimate for a time series complexity [1] (A more complex time series has more peaks, valleys etc.). |
|
Returns the percentage of values in x that are higher than t |
Returns the number of values in x that are higher than the mean of x |
|
|
Returns the percentage of values in x that are lower than t |
Returns the number of values in x that are lower than the mean of x |
|
|
Calculates a Continuous wavelet transform for the Ricker wavelet, also known as the "Mexican hat wavelet" which is defined by |
|
Calculates the sum of squares of chunk i out of N chunks expressed as a ratio with the sum of squares over the whole series. |
|
Returns the spectral centroid (mean), variance, skew, and kurtosis of the absolute fourier transform spectrum. |
|
Calculates the fourier coefficients of the one-dimensional discrete Fourier Transform for real input by fast fourier transformation algorithm |
Returns the first location of the maximum value of x. |
|
Returns the first location of the minimal value of x. |
|
|
Calculate the binned entropy of the power spectral density of the time series (using the welch method). |
|
Coefficients of polynomial |
Checks if any value in x occurs more than once |
|
Checks if the maximum value of x is observed more than once |
|
Checks if the minimal value of x is observed more than once |
|
|
Calculates the relative index i of time series x where q% of the mass of x lies left of i. |
|
Returns the kurtosis of x (calculated with the adjusted Fisher-Pearson standardized moment coefficient G2). |
|
Does time series have large standard deviation? |
Returns the relative last location of the maximum value of x. |
|
Returns the last location of the minimal value of x. |
|
|
Calculate a complexity estimate based on the Lempel-Ziv compression algorithm. |
|
Returns the length of x |
|
Calculate a linear least-squares regression for the values of the time series versus the sequence from 0 to length of the time series minus one. |
|
Calculate a linear least-squares regression for the values of the time series versus the sequence from 0 to length of the time series minus one. |
Returns the length of the longest consecutive subsequence in x that is bigger than the mean of x |
|
Returns the length of the longest consecutive subsequence in x that is smaller than the mean of x |
|
|
Calculates the 1-D Matrix Profile[1] and returns Tukey's Five Number Set plus the mean of that Matrix Profile. |
|
Largest fixed point of dynamics :math:argmax_x {h(x)=0}` estimated from polynomial |
|
Calculates the highest value of the time series x. |
|
Returns the mean of x |
Average over first differences. |
|
|
Average over time series differences. |
|
Calculates the arithmetic mean of the n absolute maximum values of the time series. |
Returns the mean value of a central approximation of the second derivative |
|
|
Returns the median of x |
|
Calculates the lowest value of the time series x. |
|
Calculates the number of crossings of x on m. |
|
Number of different peaks in x. |
|
Calculates the number of peaks of at least support n in the time series x. |
|
Calculates the value of the partial autocorrelation function at the given lag. |
Returns the percentage of non-unique data points. |
|
Returns the percentage of values that are present in the time series more than once. |
|
|
Calculate the permutation entropy. |
|
Calculates the q quantile of x. |
|
This feature calculator accepts an input query subsequence parameter, compares the query (under z-normalized Euclidean distance) to all subsequences within the time series, and returns a count of the number of times the query was found in the time series (within some predefined maximum distance threshold). |
|
Count observed values within the interval [min, max). |
|
Ratio of values that are more than r * std(x) (so r times sigma) away from the mean of x. |
Returns a factor which is 1 if all values in the time series occur only once, and below one if this is not the case. |
|
Returns the root mean square (rms) of the time series. |
|
Calculate and return sample entropy of x. |
|
|
This method returns a decorator that sets the property key of the function to value |
|
Returns the sample skewness of x (calculated with the adjusted Fisher-Pearson standardized moment coefficient G1). |
|
This feature calculator estimates the cross power spectral density of the time series x at different frequencies. |
Returns the standard deviation of x |
|
Returns the sum of all data points, that are present in the time series more than once. |
|
Returns the sum of all values, that are present in the time series more than once. |
|
|
Calculates the sum over the time series values |
|
Boolean variable denoting if the distribution of x looks symmetric. |
Returns the time reversal asymmetry statistic. |
|
|
Count occurrences of value in time series x. |
|
Returns the variance of x |
Is variance higher than the standard deviation? |
|
Returns the variation coefficient (standard error / mean, give relative value of variation around mean) of x. |
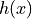 , which has been fitted to the deterministic dynamics of Langevin model
, which has been fitted to the deterministic dynamics of Langevin model