Introduction¶
Why do you need such a module?¶
tsfresh is used to to extract characteristics from time series. Let’s assume you recorded the ambient temperature around your computer over one day as the following time series:
(and yes, it is pretty cold!)
Now you want to calculate different characteristics such as the maximal or minimal temperature, the average temperature or the number of temporary temperature peaks:
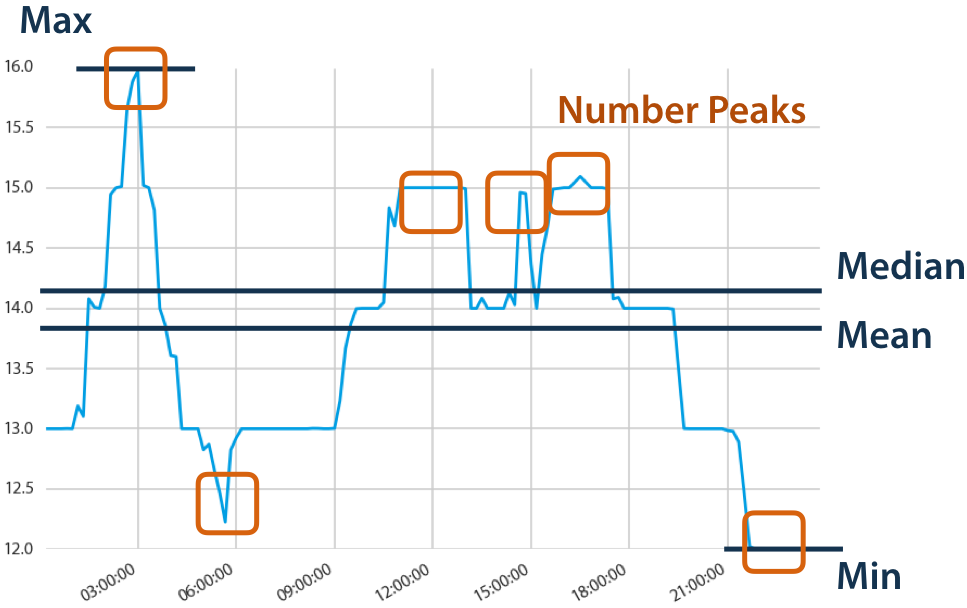
Without tsfresh, you would have to calculate all those characteristics by hand. With tsfresh this process is automated and all those features can be calculated automatically.
Further tsfresh is compatible with pythons pandas and scikit-learn APIs, two important packages for Data
Science endeavours in python.
What to do with these features?¶
The extracted features can be used to describe or cluster time series based on the extracted characteristics. Further, they can be used to build models that perform classification/regression tasks on the time series. Often the features give new insights into time series and their dynamics.
The tsfresh package has been used successfully in projects involving
- the prediction of the life span of machines
- the prediction of the quality of steel billets during a continuous casting process [1]
What not to do with tsfresh?¶
Currently, tsfresh is not suitable
- for usage with streaming data
- to train models on the features (we do not want to reinvent the wheel, check out the python package scikit-learn for example)
However, some of these use cases could be implemented, if you have an application in mind, open an issue at https://github.com/blue-yonder/tsfresh/issues, or feel free to contact us.
What else is out there?¶
There is a matlab package called hctsa which can be used to automatically extract features from time series. It is also possible to use hctsa from within python by means of the pyopy package. There also exist featuretools, FATS and cesium.
References¶
[1] Christ, M., Kempa-Liehr, A.W. and Feindt, M. (2016). Distributed and parallel time series feature extraction for industrial big data applications. ArXiv e-prints: 1610.07717 URL: http://adsabs.harvard.edu/abs/2016arXiv161007717C