tsfresh.transformers package
Submodules
tsfresh.transformers.feature_augmenter module
- class tsfresh.transformers.feature_augmenter.FeatureAugmenter(default_fc_parameters=None, kind_to_fc_parameters=None, column_id=None, column_sort=None, column_kind=None, column_value=None, timeseries_container=None, chunksize=None, n_jobs=1, show_warnings=False, disable_progressbar=False, impute_function=None, profile=False, profiling_filename='profile.txt', profiling_sorting='cumulative')[source]
Bases:
BaseEstimator,TransformerMixinSklearn-compatible estimator, for calculating and adding many features calculated from a given time series to the data. It is basically a wrapper around
extract_features().The features include basic ones like min, max or median, and advanced features like fourier transformations or statistical tests. For a list of all possible features, see the module
feature_calculators. The column name of each added feature contains the name of the function of that module, which was used for the calculation.For this estimator, two datasets play a crucial role:
the time series container with the timeseries data. This container (for the format see Data Formats) contains the data which is used for calculating the features. It must be groupable by ids which are used to identify which feature should be attached to which row in the second dataframe.
the input data X, where the features will be added to. Its rows are identifies by the index and each index in X must be present as an id in the time series container.
Imagine the following situation: You want to classify 10 different financial shares and you have their development in the last year as a time series. You would then start by creating features from the metainformation of the shares, e.g. how long they were on the market etc. and filling up a table - the features of one stock in one row. This is the input array X, which each row identified by e.g. the stock name as an index.
>>> df = pandas.DataFrame(index=["AAA", "BBB", ...]) >>> # Fill in the information of the stocks >>> df["started_since_days"] = ... # add a feature
You can then extract all the features from the time development of the shares, by using this estimator. The time series container must include a column of ids, which are the same as the index of X.
>>> time_series = read_in_timeseries() # get the development of the shares >>> from tsfresh.transformers import FeatureAugmenter >>> augmenter = FeatureAugmenter(column_id="id") >>> augmenter.set_timeseries_container(time_series) >>> df_with_time_series_features = augmenter.transform(df)
The settings for the feature calculation can be controlled with the settings object. If you pass
None, the default settings are used. Please refer toComprehensiveFCParametersfor more information.This estimator does not select the relevant features, but calculates and adds all of them to the DataFrame. See the
RelevantFeatureAugmenterfor calculating and selecting features.For a description what the parameters column_id, column_sort, column_kind and column_value mean, please see
extraction.- fit(X=None, y=None)[source]
The fit function is not needed for this estimator. It just does nothing and is here for compatibility reasons.
- Parameters:
X (Any) – Unneeded.
y (Any) – Unneeded.
- Returns:
The estimator instance itself
- Return type:
- set_timeseries_container(timeseries_container)[source]
Set the timeseries, with which the features will be calculated. For a format of the time series container, please refer to
extraction. The timeseries must contain the same indices as the later DataFrame, to which the features will be added (the one you will pass totransform()). You can call this function as often as you like, to change the timeseries later (e.g. if you want to extract for different ids).- Parameters:
timeseries_container (pandas.DataFrame or dict) – The timeseries as a pandas.DataFrame or a dict. See
extractionfor the format.- Returns:
None
- Return type:
None
- transform(X)[source]
Add the features calculated using the timeseries_container and add them to the corresponding rows in the input pandas.DataFrame X.
To save some computing time, you should only include those time serieses in the container, that you need. You can set the timeseries container with the method
set_timeseries_container().- Parameters:
X (pandas.DataFrame) – the DataFrame to which the calculated timeseries features will be added. This is not the dataframe with the timeseries itself.
- Returns:
The input DataFrame, but with added features.
- Return type:
pandas.DataFrame
tsfresh.transformers.feature_selector module
- class tsfresh.transformers.feature_selector.FeatureSelector(test_for_binary_target_binary_feature='fisher', test_for_binary_target_real_feature='mann', test_for_real_target_binary_feature='mann', test_for_real_target_real_feature='kendall', fdr_level=0.05, hypotheses_independent=False, n_jobs=1, chunksize=None, ml_task='auto', multiclass=False, n_significant=1, multiclass_p_values='min')[source]
Bases:
BaseEstimator,TransformerMixinSklearn-compatible estimator, for reducing the number of features in a dataset to only those, that are relevant and significant to a given target. It is basically a wrapper around
check_fs_sig_bh().The check is done by testing the hypothesis
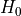 = the Feature is not relevant and can not be added`
= the Feature is not relevant and can not be added`against
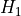 = the Feature is relevant and should be kept
= the Feature is relevant and should be keptusing several statistical tests (depending on whether the feature or/and the target is binary or not). Using the Benjamini Hochberg procedure, only features in
are rejected.This estimator - as most of the sklearn estimators - works in a two step procedure. First, it is fitted on training data, where the target is known:
>>> import pandas as pd >>> X_train, y_train = pd.DataFrame(), pd.Series() # fill in with your features and target >>> from tsfresh.transformers import FeatureSelector >>> selector = FeatureSelector() >>> selector.fit(X_train, y_train)
In this example the list of relevant features is empty:
>>> selector.relevant_features >>> []
The same holds for the feature importance:
>>> selector.feature_importances_ >>> array([], dtype=float64)
The estimator keeps track on those features, that were relevant in the training step. If you apply the estimator after the training, it will delete all other features in the testing data sample:
>>> X_test = pd.DataFrame() >>> X_selected = selector.transform(X_test)
After that, X_selected will only contain the features that were relevant during the training.
If you are interested in more information on the features, you can look into the member
relevant_featuresafter the fit.- fit(X, y)[source]
Extract the information, which of the features are relevant using the given target.
For more information, please see the
check_fs_sig_bh()function. All columns in the input data sample are treated as feature. The index of all rows in X must be present in y.- Parameters:
X (pandas.DataFrame or numpy.array) – data sample with the features, which will be classified as relevant or not
y (pandas.Series or numpy.array) – target vector to be used, to classify the features
- Returns:
the fitted estimator with the information, which features are relevant
- Return type:
- transform(X)[source]
Delete all features, which were not relevant in the fit phase.
- Parameters:
X (pandas.DataSeries or numpy.array) – data sample with all features, which will be reduced to only those that are relevant
- Returns:
same data sample as X, but with only the relevant features
- Return type:
pandas.DataFrame or numpy.array
tsfresh.transformers.per_column_imputer module
- class tsfresh.transformers.per_column_imputer.PerColumnImputer(col_to_NINF_repl_preset=None, col_to_PINF_repl_preset=None, col_to_NAN_repl_preset=None)[source]
Bases:
BaseEstimator,TransformerMixinSklearn-compatible estimator, for column-wise imputing DataFrames by replacing all
NaNsandinfswith with average/extreme values from the same columns. It is basically a wrapper aroundimpute().Each occurring
inforNaNin the DataFrame is replaced by-inf->min+inf->maxNaN->median
This estimator - as most of the sklearn estimators - works in a two step procedure. First, the
.fitfunction is called where for each column the min, max and median are computed. Secondly, the.transformfunction is called which replaces the occurances ofNaNsandinfsusing the column-wise computed min, max and median values.- fit(X, y=None)[source]
Compute the min, max and median for all columns in the DataFrame. For more information, please see the
get_range_values_per_column()function.- Parameters:
X (pandas.DataFrame) – DataFrame to calculate min, max and median values on
y (Any) – Unneeded.
- Returns:
the estimator with the computed min, max and median values
- Return type:
Imputer
- transform(X)[source]
Column-wise replace all
NaNs,-infand+infin the DataFrame X with average/extreme values from the provided dictionaries.- Parameters:
X (pandas.DataFrame) – DataFrame to impute
- Returns:
imputed DataFrame
- Return type:
pandas.DataFrame
- Raises:
RuntimeError – if the replacement dictionaries are still of None type. This can happen if the transformer was not fitted.
tsfresh.transformers.relevant_feature_augmenter module
- class tsfresh.transformers.relevant_feature_augmenter.RelevantFeatureAugmenter(filter_only_tsfresh_features=True, default_fc_parameters=None, kind_to_fc_parameters=None, column_id=None, column_sort=None, column_kind=None, column_value=None, timeseries_container=None, chunksize=None, n_jobs=1, show_warnings=False, disable_progressbar=False, profile=False, profiling_filename='profile.txt', profiling_sorting='cumulative', test_for_binary_target_binary_feature='fisher', test_for_binary_target_real_feature='mann', test_for_real_target_binary_feature='mann', test_for_real_target_real_feature='kendall', fdr_level=0.05, hypotheses_independent=False, ml_task='auto', multiclass=False, n_significant=1, multiclass_p_values='min')[source]
Bases:
BaseEstimator,TransformerMixinSklearn-compatible estimator to calculate relevant features out of a time series and add them to a data sample.
As many other sklearn estimators, this estimator works in two steps:
In the fit phase, all possible time series features are calculated using the time series, that is set by the set_timeseries_container function (if the features are not manually changed by handing in a feature_extraction_settings object). Then, their significance and relevance to the target is computed using statistical methods and only the relevant ones are selected using the Benjamini Hochberg procedure. These features are stored internally.
In the transform step, the information on which features are relevant from the fit step is used and those features are extracted from the time series. These extracted features are then added to the input data sample.
This estimator is a wrapper around most of the functionality in the tsfresh package. For more information on the subtasks, please refer to the single modules and functions, which are:
Settings for the feature extraction:
ComprehensiveFCParametersFeature extraction method:
extract_features()Extracted features:
feature_calculatorsFeature selection:
check_fs_sig_bh()
This estimator works analogue to the
FeatureAugmenterwith the difference that this estimator does only output and calculate the relevant features, whereas the other outputs all features.Also for this estimator, two datasets play a crucial role:
the time series container with the timeseries data. This container (for the format see
extraction) contains the data which is used for calculating the features. It must be groupable by ids which are used to identify which feature should be attached to which row in the second dataframe:the input data, where the features will be added to.
Imagine the following situation: You want to classify 10 different financial shares and you have their development in the last year as a time series. You would then start by creating features from the metainformation of the shares, e.g. how long they were on the market etc. and filling up a table - the features of one stock in one row.
>>> # Fill in the information of the stocks and the target >>> X_train, X_test, y_train = pd.DataFrame(), pd.DataFrame(), pd.Series()
You can then extract all the relevant features from the time development of the shares, by using this estimator:
>>> train_time_series, test_time_series = read_in_timeseries() # get the development of the shares >>> from tsfresh.transformers import RelevantFeatureAugmenter >>> augmenter = RelevantFeatureAugmenter() >>> augmenter.set_timeseries_container(train_time_series) >>> augmenter.fit(X_train, y_train) >>> augmenter.set_timeseries_container(test_time_series) >>> X_test_with_features = augmenter.transform(X_test)
X_test_with_features will then contain the same information as X_test (with all the meta information you have probably added) plus some relevant time series features calculated on the time series you handed in.
Please keep in mind that the time series you hand in before fit or transform must contain data for the rows that are present in X.
If your set filter_only_tsfresh_features to True, your manually-created features that were present in X_train (or X_test) before using this estimator are not touched. Otherwise, also those features are evaluated and may be rejected from the data sample, because they are irrelevant.
For a description what the parameters column_id, column_sort, column_kind and column_value mean, please see
extraction.You can control the feature extraction in the fit step (the feature extraction in the transform step is done automatically) as well as the feature selection in the fit step by handing in settings. However, the default settings which are used if you pass no flags are often quite sensible.
- fit(X, y)[source]
Use the given timeseries from
set_timeseries_container()and calculate features from it and add them to the data sample X (which can contain other manually-designed features).Then determine which of the features of X are relevant for the given target y. Store those relevant features internally to only extract them in the transform step.
If filter_only_tsfresh_features is True, only reject newly, automatically added features. If it is False, also look at the features that are already present in the DataFrame.
- Parameters:
X (pandas.DataFrame or numpy.array) – The data frame without the time series features. The index rows should be present in the timeseries and in the target vector.
y (pandas.Series or numpy.array) – The target vector to define, which features are relevant.
- Returns:
the fitted estimator with the information, which features are relevant.
- Return type:
- fit_transform(X, y)[source]
Equivalent to
fit()followed bytransform(); however, this is faster than performing those steps separately, because it avoids re-extracting relevant features for training data.- Parameters:
X (pandas.DataFrame or numpy.array) – The data frame without the time series features. The index rows should be present in the timeseries and in the target vector.
y (pandas.Series or numpy.array) – The target vector to define, which features are relevant.
- Returns:
a data sample with the same information as X, but with added relevant time series features and deleted irrelevant information (only if filter_only_tsfresh_features is False).
- Return type:
pandas.DataFrame
- set_timeseries_container(timeseries_container)[source]
Set the timeseries, with which the features will be calculated. For a format of the time series container, please refer to
extraction. The timeseries must contain the same indices as the later DataFrame, to which the features will be added (the one you will pass totransform()orfit()). You can call this function as often as you like, to change the timeseries later (e.g. if you want to extract for different ids).- Parameters:
timeseries_container (pandas.DataFrame or dict) – The timeseries as a pandas.DataFrame or a dict. See
extractionfor the format.- Returns:
None
- Return type:
None
- transform(X)[source]
After the fit step, it is known which features are relevant, Only extract those from the time series handed in with the function
set_timeseries_container().If filter_only_tsfresh_features is False, also delete the irrelevant, already present features in the data frame.
- Parameters:
X (pandas.DataFrame or numpy.array) – the data sample to add the relevant (and delete the irrelevant) features to.
- Returns:
a data sample with the same information as X, but with added relevant time series features and deleted irrelevant information (only if filter_only_tsfresh_features is False).
- Return type:
pandas.DataFrame
Module contents
The module transformers contains several transformers which can be used inside a sklearn pipeline.